Orchestracot の CLI 操作
前回に引き続き、Presslabs の mysql-operator です。今回は failover 周りの動作を確認します。Orchestrator の操作は Web UI からも操作できますが、コマンドラインで試します。
orchestrator コマンド
kubectl exec -it mysql-operator-0 -c orchestrator shちょっとログが邪魔なので stderr は /dev/null に捨ててます。
$ /usr/local/orchestrator/orchestrator --ignore-raft-setup -config /etc/orchestrator/orchestrator.conf.json -c clusters 2> /dev/null
mycluster-mysql-cluster-db-mysql-0.mysql.default:3306$ /usr/local/orchestrator/orchestrator --ignore-raft-setup -config /etc/orchestrator/orchestrator.conf.json -c topolog
y -i mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 2> /dev/null
mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]ただ、--ignore-raft-setup というちょっと怪しげなオプションを指定する必要があって、Orchestrator をクラスタ構成としている場合は使ってはダメかも。
orchestrator-client コマンド
ということで Web API 経由でアクセスする orchestrator-client を使います。これは bash script です。
curl -LO https://raw.githubusercontent.com/openark/orchestrator/master/resources/bin/orchestrator-client
chmod +x orchestrator-client
export ORCHESTRATOR_API=$(minikube service mysql-operator --url)/api$ ./orchestrator-client -c clusters
mycluster-mysql-cluster-db-mysql-0.mysql.default:3306$ ./orchestrator-client -c topology -i mycluster-mysql-cluster-db-mysql-0.mysql.default:3306
mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]orchestrator-client -h でコマンドの help が確認できます。
master の takeover / failover
Master の障害が検知されれば自動で replica が昇格します(後半で検証)が、ダウンタイムが発生します。正常な状態で切り替えるには graceful-master-takeover コマンドを使います。1秒未満の瞬断で切り替えられます。トランザクション中だったものがどうなるかは未確認。
$ ./orchestrator-client -c graceful-master-takeover
orchestrator-client[42884]: instance|alias must be providedクラスタの instance か alias を指定する必要があります。clusters か clusters-alias コマンドで確認できます。
$ ./orchestrator-client -c clusters
mycluster-mysql-cluster-db-mysql-0.mysql.default:3306$ ./orchestrator-client -c clusters-alias
mycluster-mysql-cluster-db-mysql-0.mysql.default:3306,mycluster-mysql-cluster-db.default今回は alias の mycluster-mysql-cluster-db.default で指定してみます。
$ ./orchestrator-client -c graceful-master-takeover -a mycluster-mysql-cluster-db.default
When no target instance indicated, master mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 should only have one replica (making the takeover safe and simple), but has 2. Abortingどれを新しい master にするか指定しないとダメでした。mycluster-mysql-cluster-db-mysql-1 を新しい master にすることにします。
$ ./orchestrator-client -c graceful-master-takeover -a mycluster-mysql-cluster-db.default -d mycluster-mysql-cluster-db-mysql-1.mysql.default:3306
mycluster-mysql-cluster-db-mysql-1.mysql.default:3306$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
- mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,ro,ROW,>>,GTID,downtimed]
+ mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [1s,ok,5.7.26-29-log,ro,ROW,>>,GTID]master が切り替わりました。旧 master は外れました。
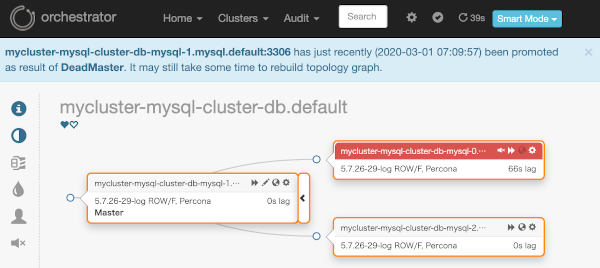
$ kubectl get pod --show-labels -l mysql.presslabs.org/cluster=mycluster-mysql-cluster-db
NAME READY STATUS RESTARTS AGE LABELS
mycluster-mysql-cluster-db-mysql-0 4/4 Running 0 15h app.kubernetes.io/component=database,app.kubernetes.io/instance=mycluster-mysql-cluster-db,app.kubernetes.io/managed-by=mysql.presslabs.org,app.kubernetes.io/name=mysql,app.kubernetes.io/version=5.7.26,controller-revision-hash=mycluster-mysql-cluster-db-mysql-58f489bb77,healthy=no,mysql.presslabs.org/cluster=mycluster-mysql-cluster-db,role=replica,statefulset.kubernetes.io/pod-name=mycluster-mysql-cluster-db-mysql-0
mycluster-mysql-cluster-db-mysql-1 4/4 Running 0 15h app.kubernetes.io/component=database,app.kubernetes.io/instance=mycluster-mysql-cluster-db,app.kubernetes.io/managed-by=mysql.presslabs.org,app.kubernetes.io/name=mysql,app.kubernetes.io/version=5.7.26,controller-revision-hash=mycluster-mysql-cluster-db-mysql-58f489bb77,healthy=yes,mysql.presslabs.org/cluster=mycluster-mysql-cluster-db,role=master,statefulset.kubernetes.io/pod-name=mycluster-mysql-cluster-db-mysql-1
mycluster-mysql-cluster-db-mysql-2 4/4 Running 0 15h app.kubernetes.io/component=database,app.kubernetes.io/instance=mycluster-mysql-cluster-db,app.kubernetes.io/managed-by=mysql.presslabs.org,app.kubernetes.io/name=mysql,app.kubernetes.io/version=5.7.26,controller-revision-hash=mycluster-mysql-cluster-db-mysql-58f489bb77,healthy=yes,mysql.presslabs.org/cluster=mycluster-mysql-cluster-db,role=replica,statefulset.kubernetes.io/pod-name=mycluster-mysql-cluster-db-mysql-2mycluster-mysql-cluster-db-mysql-0 はもう replica でもありません。
この状態で mysql-0 の pod を delete すれば起動時に replication 設定されて replica として復帰するはずですがバグってて mysql-0 だけは復活しないようです。
試しに mysql-2 pod を delete してみます。
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
- mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,ro,ROW,>>,GTID,downtimed]
- mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [unknown,invalid,5.7.26-29-log,ro,ROW,>>,GTID]停止中は unknown,invalid になってしまいますが
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
- mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,ro,ROW,>>,GTID,downtimed]
+ mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]復活しました 😀
mysql-2 の起動時には mysql-1 から extrabackup で取得しています。
$ kubectl logs mycluster-mysql-cluster-db-mysql-2 -c init
Create rclone.conf file.
2020-03-01T08:04:04.721Z INFO sidecar environment is not set {"key": "MY_SERVER_ID_OFFSET"}
2020-03-01T08:04:04.721Z INFO sidecar environment is not set {"key": "INIT_BUCKET_URI"}
2020-03-01T08:04:04.721Z INFO sidecar cloning command {"host": "mycluster-mysql-cluster-db-mysql-2"}
2020-03-01T08:04:04.721Z INFO sidecar cloning from node {"host": "mycluster-mysql-cluster-db-mysql-1.mysql.default"}
2020-03-01T08:04:04.721Z INFO sidecar initialize a backup {"host": "mycluster-mysql-cluster-db-mysql-1.mysql.default", "endpoint": "/xbackup"}
xtrabackup: recognized server arguments: --innodb_checksum_algorithm=crc32 --innodb_log_checksum_algorithm=strict_crc32 --innodb_data_file_path=ibdata1:12M:autoextend --innodb_log_files_in_group=2 --innodb_log_file_size=50331648 --innodb_fast_checksum=0 --innodb_page_size=16384 --innodb_log_block_size=512 --innodb_undo_directory=./ --innodb_undo_tablespaces=0 --server-id=101 --redo-log-version=1
...
...一方、mysql-0 では nothing to clone or init from となってしまっています 🤔
$ k logs mycluster-mysql-cluster-db-mysql-0 -c init
Create rclone.conf file.
2020-03-01T07:36:30.420Z INFO sidecar environment is not set {"key": "MY_SERVER_ID_OFFSET"}
2020-03-01T07:36:30.421Z INFO sidecar environment is not set {"key": "INIT_BUCKET_URI"}
2020-03-01T07:36:30.422Z INFO sidecar cloning command {"host": "mycluster-mysql-cluster-db-mysql-0"}
2020-03-01T07:36:30.422Z INFO sidecar nothing to clone or init from
2020-03-01T07:36:30.422Z INFO sidecar configuring server {"host": "mycluster-mysql-cluster-db-mysql-0"}
2020-03-01T07:36:30.422Z INFO sidecar error while reading PURGE GTID from xtrabackup info file {"error": "open /var/lib/mysql/xtrabackup_binlog_info: no such file or directory"}で、コードを探してみると v0.3.8 には nothing to clone or init from がありますが、最新の master branch ではもう修正されているっぽいです。現在の仕様は次のようになっているみたいです。
pkg/sidecar/appclone.go#L29-L58
// RunCloneCommand clones the data from several potential sources.
//
// There are a few possible scenarios that this function tries to handle:
//
// Scenario | Action Taken
// ------------------------------------------------------------------------------------
// Data already exists | Log an informational message and return without error.
// | This permits the pod to continue initializing and mysql
// | will use the data already on the PVC.
// ------------------------------------------------------------------------------------
// Healthy replicas exist | We will attempt to clone from the healthy replicas.
// | If the cloning starts but is interrupted, we will return
// | with an error, not trying to clone from the master. The
// | assumption is that some intermittent error caused the
// | failure and we should let K8S restart the init container
// | to try to clone from the replicas again.
// ------------------------------------------------------------------------------------
// No healthy replicas; only | We attempt to clone from the master, assuming that this
// master exists | is the initialization of the second pod in a multi-pod
// | cluster. If cloning starts and is interrupted, we will
// | return with an error, letting K8S try again.
// ------------------------------------------------------------------------------------
// No healthy replicas; no | If there is a bucket URL to clone from, we will try that.
// master; bucket URL exists | The assumption is that this is the bootstrap case: the
// | very first mysql pod is being initialized.
// ------------------------------------------------------------------------------------
// No healthy replicas; no | If this is the first pod in the cluster, then allow it
// master; no bucket URL | to initialize as an empty instance, otherwise, return an
// | error to allow k8s to kill and restart the pod.
// ------------------------------------------------------------------------------------新しい image はあるみたいなので helm repository からではなく git repository の master にある helm chart からインストールして確認してみます。
おや、新しい version では replica 用の Service が追加されていますね。
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 28m
mycluster-mysql-cluster-db-mysql ClusterIP 10.111.142.169 3306/TCP 15m
mycluster-mysql-cluster-db-mysql-master ClusterIP 10.109.199.43 3306/TCP,8080/TCP 15m
mycluster-mysql-cluster-db-mysql-replicas ClusterIP 10.97.48.190 3306/TCP,8080/TCP 15m
mysql ClusterIP None 3306/TCP,9125/TCP 15m
mysql-operator NodePort 10.98.93.157 80:32120/TCP 21m
mysql-operator-0-svc ClusterIP 10.105.168.29 80/TCP,10008/TCP 21m Master 混在の Service は使いづらそうだなと思っていたのでこれは良い進化。
で、肝心の mysql-0 がきちんと復帰するかどうかの確認です。
$ k logs mycluster-mysql-cluster-db-mysql-0 -c init
Create rclone.conf file.
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "MY_SERVER_ID_OFFSET"}
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "INIT_BUCKET_URI"}
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "RCLONE_EXTRA_ARGS"}
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "XBSTREAM_EXTRA_ARGS"}
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "XTRABACKUP_EXTRA_ARGS"}
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "XTRABACKUP_PREPARE_EXTRA_ARGS"}
2020-03-01T11:57:57.579Z INFO sidecar environment is not set {"key": "XTRABACKUP_TARGET_DIR"}
2020-03-01T11:57:57.579Z INFO sidecar cloning command {"host": "mycluster-mysql-cluster-db-mysql-0"}
2020-03-01T11:57:57.581Z INFO sidecar cloning from node {"host": "mycluster-mysql-cluster-db-mysql-replicas"}
2020-03-01T11:57:57.581Z INFO sidecar initialize a backup {"host": "mycluster-mysql-cluster-db-mysql-replicas", "endpoint": "/xbackup"}
xtrabackup: recognized server arguments: --innodb_checksum_algorithm=crc32 --innodb_log_checksum_algorithm=strict_crc32 --innodb_data_file_path=ibdata1:12M:autoextend --innodb_log_files_in_group=2 --innodb_log_file_size=50331648 --innodb_fast_checksum=0 --innodb_page_size=16384 --innodb_log_block_size=512 --innodb_undo_directory=./ --innodb_undo_tablespaces=0 --server-id=102 --redo-log-version=1
xtrabackup: recognized client arguments: --prepare=1 --target-dir=/var/lib/mysql
xtrabackup version 2.4.18 based on MySQL server 5.7.26 Linux (x86_64) (revision id: 29b4ca5)
...
...正しく復帰しました。そして、 replica 専用 Service から xtrabackup で取得しています。ヤッタネ 😉
Master 障害時の動作確認
Master になっていた mysql-1 を delete pod すると程なくして mysql client からのアクセスがエラーとなりました。ERROR 2003 (HY000): Can't connect to MySQL server on '10.109.199.43' (111)。これが15秒程度続き、mysql-2 が Master に昇格しました。ここで3秒程度は Read Only 状態でしたが、その後 Writable に変更されました。
mysql-1 が Master で正常な状態から開始。
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]mysql-1 にアクセスできなくなった初期状態です。
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [unknown,invalid,5.7.26-29-log,rw,ROW,>>,GTID]
- mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,ro,ROW,>>,GTID]
- mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,ro,ROW,>>,GTID]mysql-2 を Master に昇格させたところ。まだ ReadOnly のままです。
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,ro,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [14s,ok,5.7.26-29-log,ro,ROW,>>,GTID]mysql-2 は Writable になり、再起動してきた mysql-1 は replica として初期化されました。しかし、新 Master の mysql-2 にはまだ slave としての設定が残っているため、null,noreplicationg となっています。自動で処理されるのはここまでです。
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [null,nonreplicating,5.7.26-29-log,rw,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]mysql-2 から slave 設定を削除するために reset-replica コマンドを実行する。これは手動で実行します。
$ ./orchestrator-client -c reset-replica -i mycluster-mysql-cluster-db-mysql-2.mysql.default:3306
mycluster-mysql-cluster-db-mysql-2.mysql.default:3306これでキレイな状態になりました。
$ ./orchestrator-client -c topology -a mycluster-mysql-cluster-db.default
mycluster-mysql-cluster-db-mysql-2.mysql.default:3306 [0s,ok,5.7.26-29-log,rw,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-0.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]
+ mycluster-mysql-cluster-db-mysql-1.mysql.default:3306 [0s,ok,5.7.26-29-log,ro,ROW,>>,GTID]Master が何かおかしいけど orchestrator で検知できないような場合は手動で force-master-failover か force-master-takeover コマンドを実行する必要があります。
今回はここまで。


 amazon.co.jp
amazon.co.jp